
Kimi K2.7 Code: benchmark, prezzi e confronto con GPT-5.5 e Opus 4.8
Il modello agentico di Moonshot punta su coding lungo, tool use e costo API basso
Kimi K2.7 Code è il modello agentico per coding con cui Moonshot prova a spostare la gara su un terreno pratico: task lunghi, tool use, contesto 256K e costo per token basso. Nei benchmark ufficiali migliora nettamente K2.6 e si avvicina ai frontier in alcuni test, ma la vera domanda è se il rapporto prezzo/prestazioni basta per preferirlo nei workflow reali.
Risposta breve
Kimi K2.7 Code è interessante per coding agent, task lunghi e workflow con tool use quando il costo conta quasi quanto il primo posto nei benchmark. Non supera GPT-5.5 in modo generale e non domina Opus 4.8, ma combina pesi aperti, contesto 256K, cache economica e buoni risultati agentici.
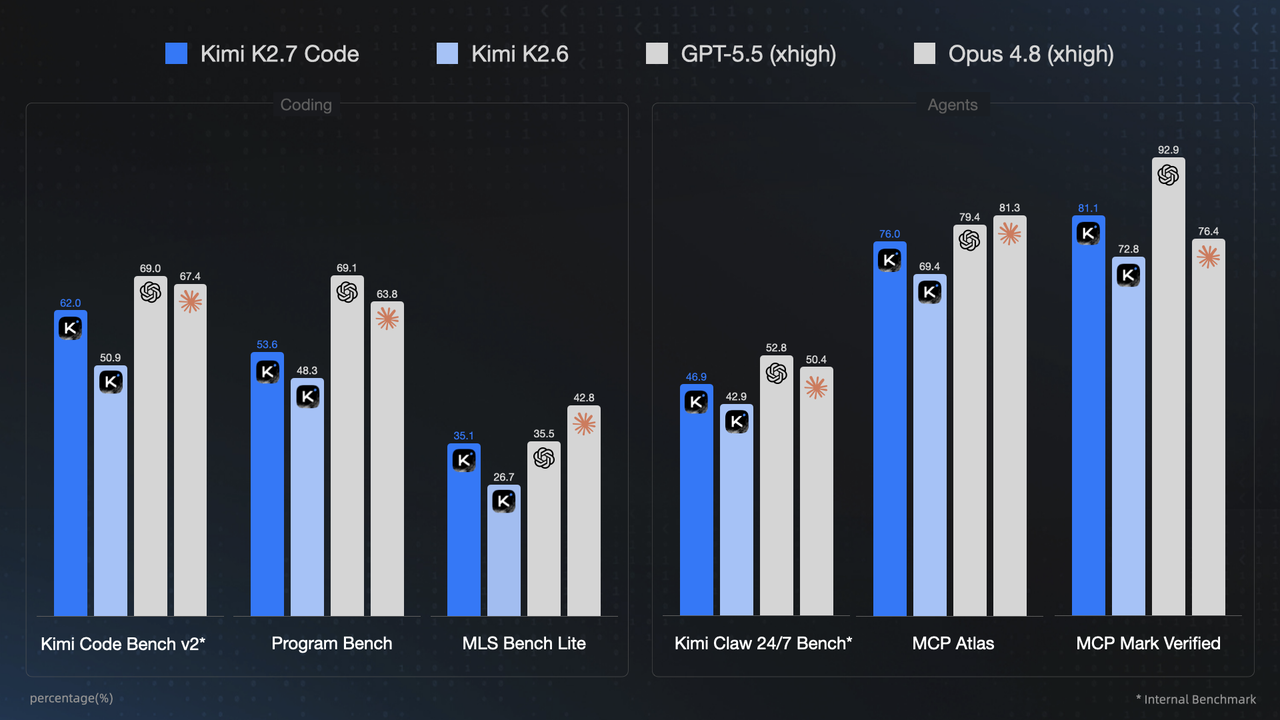
- Kimi K2.7 Code batte K2.6 in tutti i benchmark pubblicati da Moonshot.
- GPT-5.5 è sopra Kimi su Kimi Code Bench v2, Program Bench, Kimi Claw 24/7, MCP Atlas e MCP Mark Verified.
- Kimi costa $0,95 per 1M token input cache miss e $4 output: se le prestazioni sono abbastanza vicine per il tuo workflow, il risparmio può contare più del primo posto.
Grafici e benchmark citati
Confronto rapido
| Criterio | Kimi K2.7 Code | GPT-5.5 e Claude Opus 4.8 |
|---|---|---|
| Kimi Code Bench v2 | 62,0 contro 50,9 di K2.6. Moonshot dichiara un miglioramento del 21,8% rispetto al modello precedente. | GPT-5.5 è a 69,0 e Claude Opus 4.8 a 67,4. Kimi si avvicina, ma non guida il benchmark. |
| Program Bench | 53,6 contro 48,3 di K2.6. Il miglioramento esiste, ma è meno netto che su altri test. | GPT-5.5 è a 69,1 e Claude Opus 4.8 a 63,8. Qui Kimi resta chiaramente dietro. |
| MLS Bench Lite | 35,1 contro 26,7 di K2.6. È il salto relativo più forte tra i tre benchmark coding citati. | GPT-5.5 è quasi pari a 35,5, mentre Claude Opus 4.8 è più avanti a 42,8. |
| Kimi Claw 24/7 Bench | 46,9 contro 42,9 di K2.6. Misura task agentici lunghi nel benchmark interno Moonshot. | GPT-5.5 è a 52,8 e Claude Opus 4.8 a 50,4. Kimi migliora, ma non supera i due frontier. |
| MCP Atlas | 76,0 contro 69,4 di K2.6. È un buon segnale per tool use e task basati su MCP. | GPT-5.5 è a 79,4 e Claude Opus 4.8 a 81,3. Opus resta davanti su questo test. |
| MCP Mark Verified | 81,1 contro 72,8 di K2.6. È il risultato più favorevole a Kimi nel confronto con Claude. | GPT-5.5 è ancora sopra a 92,9, ma Claude Opus 4.8 è sotto a 76,4. |
Numeri operativi
Questi dati aiutano a leggere i benchmark insieme a costo, contesto e disponibilità. I risultati sono quelli dichiarati da Moonshot nel materiale ufficiale del 13 giugno 2026.
Prezzo API
Fonte: pricing Kimi · 1M token
Dato
$0,19 cache hit, $0,95 cache miss, $4 output
Lettura pratica
Molto competitivo per esperimenti, agenti e workflow con contesto riusato.
Il costo è uno dei motivi principali per testare Kimi, soprattutto quando il contesto viene riusato spesso.
Contesto
Fonte: docs Kimi · Finestra massima
Dato
262.144 token
Lettura pratica
Adatto a repository, sessioni lunghe e task multi-step, se il costo del contesto resta sotto controllo.
Il contesto 256K è utile per coding agent e repository grandi, ma non elimina il bisogno di selezionare bene i file.
Architettura
Fonte: model card · MoE
Dato
1T parametri totali, 32B attivi
Lettura pratica
Pesi disponibili su Hugging Face, ma il modello è grande e non è una scelta semplice da eseguire in locale.
La disponibilità dei pesi aumenta il controllo, ma richiede competenze e infrastruttura adeguate.
Thinking mode
Fonte: docs Kimi · Modalità obbligatoria
Dato
Sempre attivo su K2.7 Code
Lettura pratica
Utile per task complessi, meno flessibile se vuoi risposte rapide o non ragionate.
Il thinking obbligatorio spinge il modello verso task complessi, ma può essere eccessivo per richieste semplici.
Che cosa porta Kimi K2.7 Code
Moonshot presenta Kimi K2.7 Code come un modello agentico open-source focalizzato sul coding. Il suo spazio naturale non è la chat generica, ma il lavoro software che richiede più passaggi: leggere molto contesto, usare strumenti, completare task lunghi e mantenere coerenza durante una sessione di sviluppo.
- È il modello di default in Kimi Code e può essere usato anche via Kimi API.
- Supporta una finestra di contesto da 262.144 token.
- I pesi sono disponibili su Hugging Face con licenza modified MIT.
- La modalità thinking è sempre attiva su K2.7 Code.
La storia vera è il salto da K2.6
La parte più solida dei numeri è il confronto interno: Kimi K2.7 Code migliora K2.6 su tutti i benchmark pubblicati. Moonshot dichiara guadagni importanti su coding e agenti, con circa 30% di thinking-token in meno rispetto a K2.6.
- Kimi Code Bench v2: 62,0 contro 50,9.
- Program Bench: 53,6 contro 48,3.
- MLS Bench Lite: 35,1 contro 26,7.
- MCP Mark Verified: 81,1 contro 72,8.
- Moonshot dichiara più efficienza di ragionamento, non solo punteggi più alti.
Dove Kimi si avvicina ai frontier
Kimi diventa interessante quando il primo posto assoluto non è l'unico criterio. Su MLS Bench Lite è quasi allineato a GPT-5.5. Su MCP Mark Verified supera Claude Opus 4.8. Se il tuo criterio è combinare costo basso, pesi aperti e capacità agentiche, questi due segnali sono i più importanti.
- MLS Bench Lite: Kimi 35,1, GPT-5.5 35,5, Opus 42,8.
- MCP Mark Verified: Kimi 81,1, GPT-5.5 92,9, Opus 76,4.
- Il vantaggio rispetto a Claude non è generale: appare in quel benchmark specifico.
- Il prezzo API rende Kimi più facile da testare su carichi grandi o ripetuti.
Il punto economico: quasi frontier a costo più basso
Il prezzo è parte della decisione, non una nota a margine. Kimi K2.7 Code non deve battere GPT-5.5 in ogni benchmark per essere utile: deve essere abbastanza vicino nei task giusti e costare abbastanza meno da rendere sostenibili più tentativi, più contesto e più automazioni.
- Kimi dichiara $0,95 per 1M token input cache miss e $0,19 con cache hit.
- L'output costa $4 per 1M token, quindi il modello è più facile da sperimentare su agenti e task ripetuti.
- Il context caching può pesare molto se riusi lo stesso repository o la stessa base documentale.
- Se il task è critico e il primo tentativo deve riuscire, GPT-5.5 o Opus possono ancora giustificare un costo più alto.
Dove GPT-5.5 e Opus restano avanti
I numeri non sostengono una lettura tipo Kimi batte tutti. GPT-5.5 è davanti in cinque benchmark su sei tra quelli mostrati. Claude Opus 4.8 resta sopra Kimi su Program Bench, MLS Bench Lite, Kimi Claw 24/7 Bench e MCP Atlas. Kimi è competitivo, non dominante.
- GPT-5.5 è il riferimento più alto nella tabella, soprattutto su MCP Mark Verified.
- Opus 4.8 resta forte su MLS Bench Lite e MCP Atlas.
- Kimi Code Bench v2 e Kimi Claw 24/7 sono benchmark interni Moonshot: vanno letti con cautela extra.
- Per una decisione importante, questi numeri vanno affiancati a test sul tuo repository.
Quando scegliere Kimi K2.7 Code
Kimi K2.7 Code ha senso quando il progetto richiede un modello coding agentico, ma il budget non permette di usare sempre il modello più costoso. È una scelta da provare su task ripetuti, agenti interni, refactor estesi e workflow in cui il context caching può abbassare davvero il costo operativo.
- Provalo se il costo per token è una variabile importante.
- Provalo se vuoi accesso ai pesi e possibilità di deployment più controllato.
- Provalo su coding agent, MCP, refactor e task lunghi con contesto ampio.
- Evitalo come modello generalista: Moonshot stessa consiglia K2.6 per scrittura, analisi e conversazione generica.
Quando scegliere GPT-5.5 o Opus 4.8
Se il task è critico, poco ripetibile o costoso da correggere, il modello con lo score più alto può restare la scelta più razionale anche a prezzo maggiore. Nei dati Moonshot, GPT-5.5 è il riferimento più forte della tabella. Opus 4.8 resta avanti su diversi benchmark e può essere preferibile quando qualità e affidabilità pesano più del costo per token.
- Scegli GPT-5.5 quando conta la performance più alta nella tabella Moonshot.
- Scegli Opus 4.8 quando vuoi privilegiare qualità elevata e risultati più stabili sui benchmark in cui è davanti.
- Scegli Kimi quando costo, apertura dei pesi o sperimentazione agentica pesano più del primo posto assoluto.
- Confronta sempre i modelli sul tuo codice: i benchmark non sostituiscono un pilot controllato.
Domande frequenti
Kimi K2.7 Code batte GPT-5.5?
No, non in modo generale nei benchmark pubblicati da Moonshot. GPT-5.5 è sopra Kimi su cinque benchmark su sei. Kimi è quasi pari su MLS Bench Lite e resta interessante per prezzo, pesi aperti e contesto lungo.
Kimi K2.7 Code batte Claude Opus 4.8?
Solo in alcuni dati. Nel grafico Moonshot, Kimi supera Opus 4.8 su Kimi Code Bench v2 e MCP Mark Verified, ma resta sotto su Program Bench, MLS Bench Lite, Kimi Claw 24/7 Bench e MCP Atlas.
Kimi K2.7 Code è open source?
Moonshot lo presenta come open-source e pubblica i pesi su Hugging Face con licenza modified MIT. Per usi commerciali o prodotti ad ampia scala conviene leggere la licenza completa prima di costruirci sopra.
Kimi K2.7 Code va bene per uso non tecnico?
Non è la scelta più naturale. Moonshot posiziona K2.7 Code come modello per coding e workflow agentici. Per scrittura, analisi e conversazione generale indica K2.6 come opzione più bilanciata.
Perché conta il thinking mode obbligatorio?
Perché rende il modello più orientato al ragionamento lungo, ma riduce la flessibilità. Non puoi usare K2.7 Code in modalità non-thinking: se disattivi thinking in Kimi Code, la richiesta viene servita da K2.6.
La newsletter di QualeAI
Resta sempre aggiornato sul mondo AI
Ricevi aggiornamenti editoriali sui nostri approfondimenti, tool AI, modelli e workflow da conoscere.
