
Fable 5 vs GPT, Gemini e altri modelli frontier: cosa dicono davvero i benchmark
Numeri, grafici e limiti da leggere prima di scegliere il modello
Fable 5 è disponibile su Claude e via API. Max e i posti premium di Team ed Enterprise lo includono fino al 50% del limite settimanale; Pro e i posti standard richiedono usage credits. I benchmark mostrano punti di forza nel coding agentico, nel knowledge work e nei task lunghi, ma costo, velocità ed ecosistema restano decisivi.
Risposta breve
Fable 5 è incluso su Max e sui posti premium di Team ed Enterprise fino al 50% del limite settimanale; su Pro e sui posti standard usa usage credits. I benchmark indicano un vantaggio sui task agentici difficili, ma non lo rendono automaticamente la scelta migliore: costo, velocità, disponibilità ed ecosistema restano decisivi.
- Dal 20 luglio 2026, Max e i posti premium includono Fable 5; Pro e i posti standard richiedono usage credits.
- Se il lavoro deve partire ora, scegli tra Fable 5, Opus 4.8, GPT e Gemini in base a task, costo, limiti e disponibilità.
- Artificial Analysis lo presenta come modello ad alta intelligence, ma con prezzo blended alto: 8,2 dollari per 1M token contro 4,3 di GPT-5.5 thinking e 1,7 di Gemini 3.1 Pro Preview.
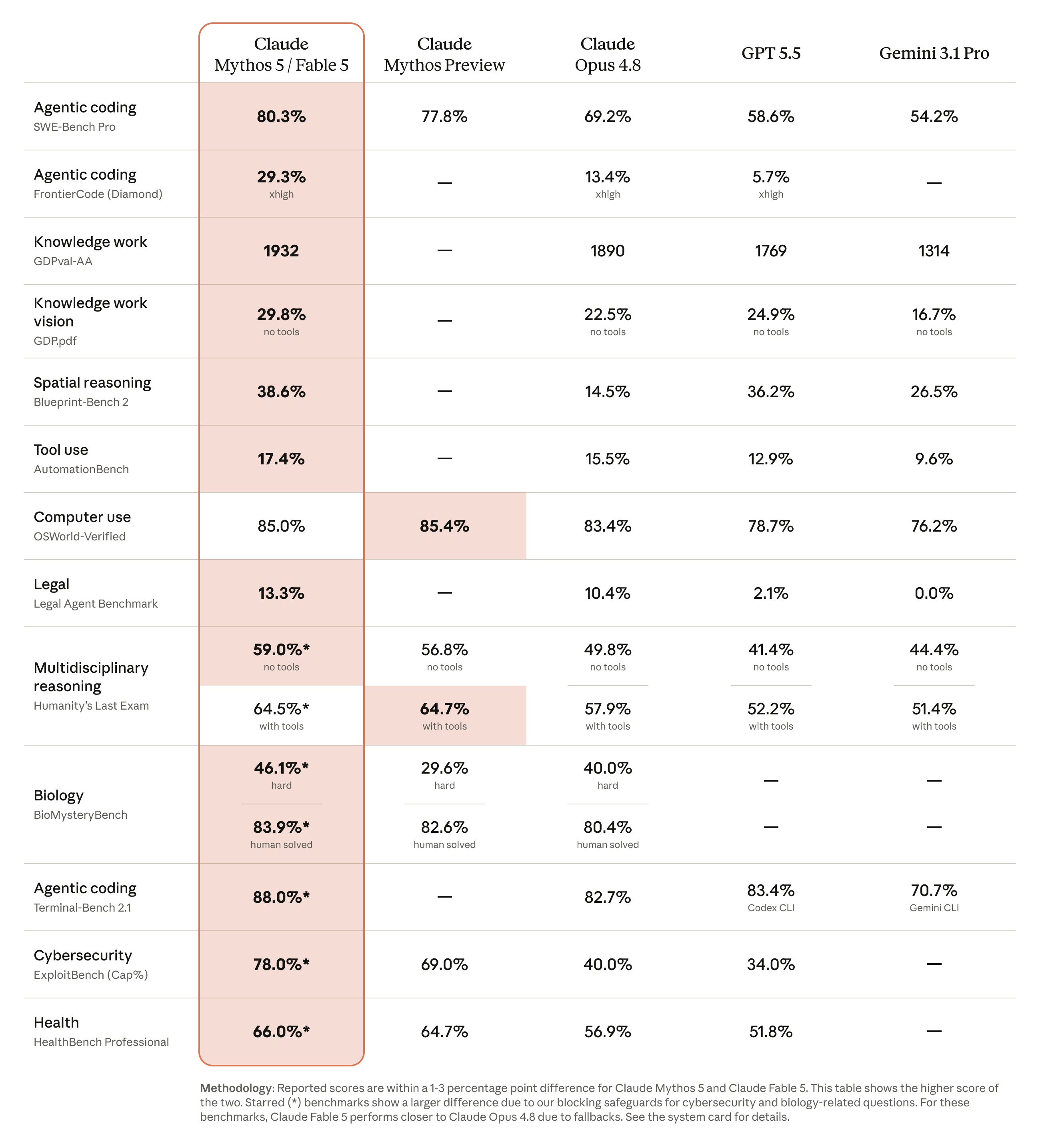
- La tabella Anthropic mostra vantaggi forti su SWE-Bench Pro, FrontierCode, GDPval-AA, Blueprint-Bench 2, Terminal-Bench 2.1, cybersecurity e health.
Grafici e benchmark citati
Confronto rapido
| Criterio | Dato o fonte | Lettura pratica |
|---|---|---|
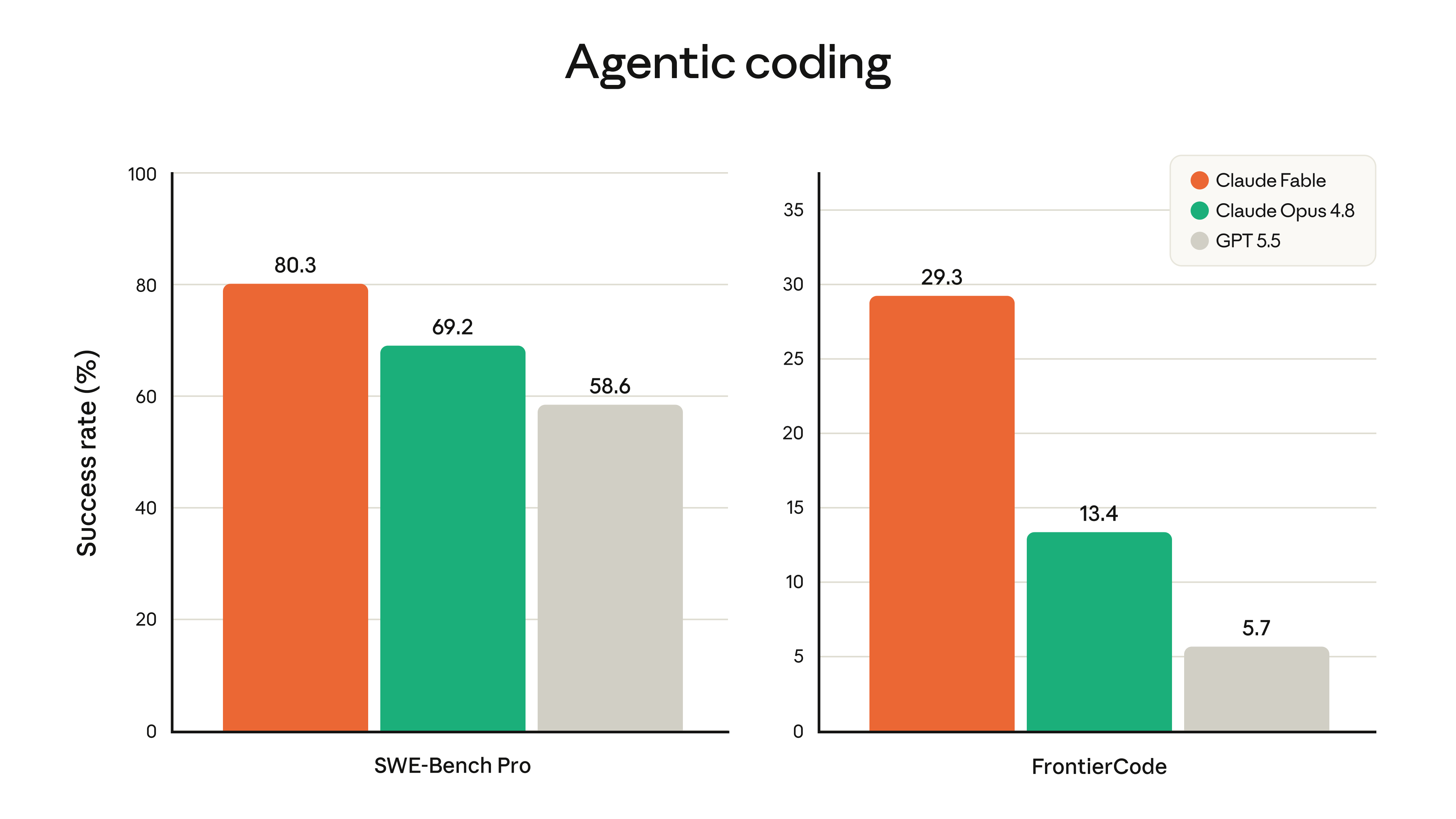
| SWE-Bench Pro | Fable 5 80,3%, Opus 4.8 69,2%, GPT-5.5 58,6%, Gemini 3.1 Pro 54,2% | È il segnale più diretto sul coding agentico: Fable ha un margine largo, ma il risultato è nella tabella ufficiale Anthropic. |
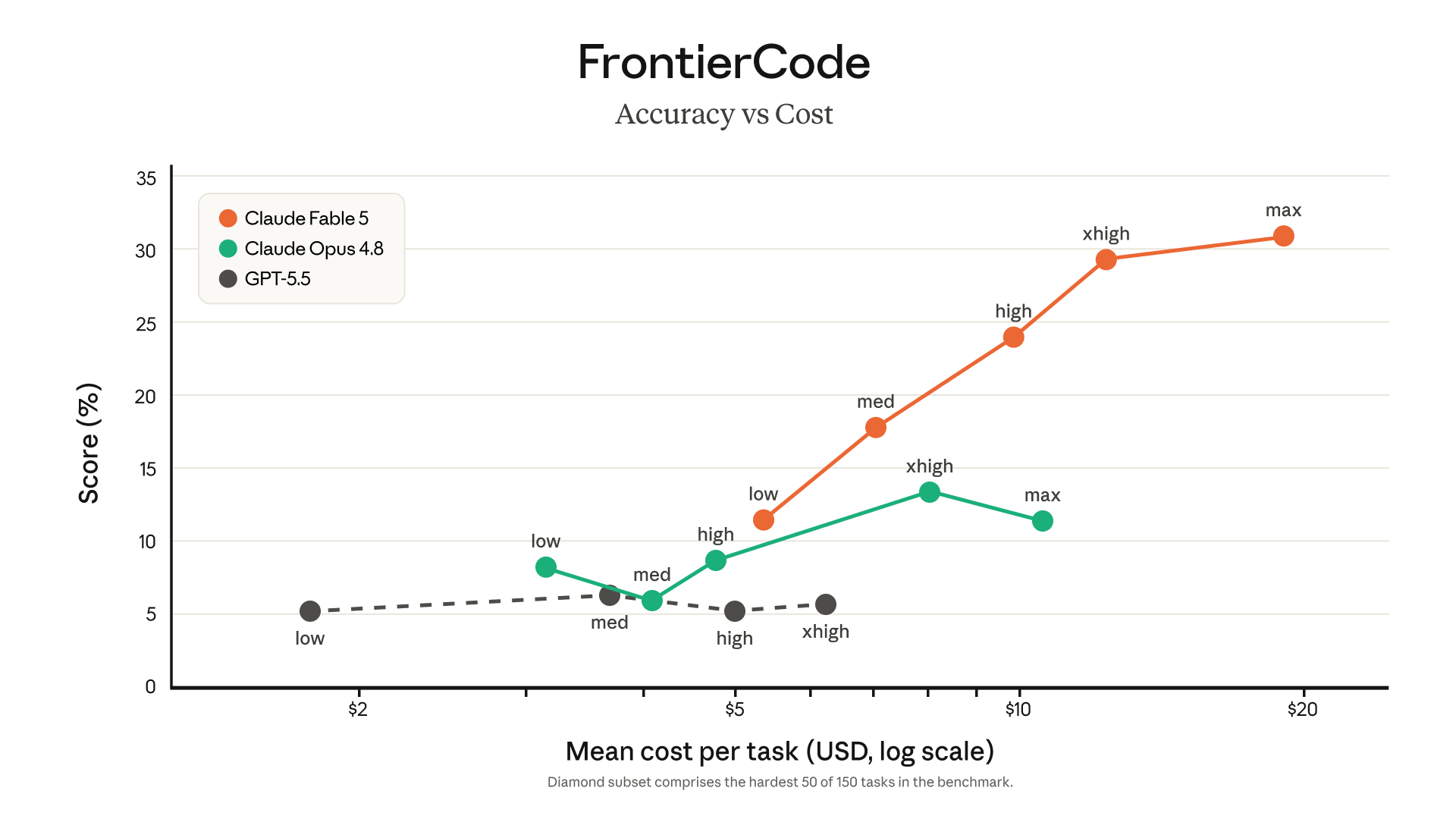
| FrontierCode Diamond | Fable 5 29,3%, Opus 4.8 13,4%, GPT-5.5 5,7%. Gemini non è riportato nella tabella | Qui emerge il vantaggio sui task coding più duri. Il grafico accuracy/cost però mostra che il vantaggio arriva pagando più effort e più costo. |
| GDPval-AA | Fable 5 1932, Opus 4.8 1890, GPT-5.5 1769, Gemini 3.1 Pro 1314 | È il numero più chiaro sul knowledge work. Artificial Analysis conferma il primato di Fable, con una nota importante sui fallback. |
| Blueprint-Bench 2 | Fable 5 38,6%, Opus 4.8 14,5%, GPT-5.5 36,2%, Gemini 3.1 Pro 26,5% | Il vantaggio non è solo coding: Fable risulta forte anche su ragionamento spaziale e compiti con struttura visiva. |
| Terminal-Bench 2.1 | Fable 5 88,0%, Opus 4.8 82,7%, GPT-5.5 con Codex CLI 83,4%, Gemini CLI 70,7% | Per agenti che usano terminale e strumenti, Fable è davanti nella tabella Anthropic, ma GPT con Codex CLI resta vicino. |
| Artificial Analysis highlights | Intelligence 65, speed 60 token/s, price blended 8,2 dollari per 1M token nella homepage Artificial Analysis | Questa è la sintesi più utile: Fable sembra premium e costoso, non un modello da usare automaticamente per ogni prompt. |
Numeri da guardare
Questi numeri non sono una classifica universale. Servono a capire quale fonte misura knowledge work, coding agentico, preferenza umana o costo operativo.
Intelligence
Fonte: Artificial Analysis · Indice proprietario
Numero
65
Cosa significa
#1 nel grafico
Il vantaggio di Fable è soprattutto nella capacità complessiva su task difficili, non nella comodità o nel prezzo.
Speed
Fonte: Artificial Analysis · Output token/s
Numero
60
Cosa significa
Molto sotto i leader
Fable non sembra il modello da scegliere se il criterio principale è la velocità di risposta.
Prezzo
Fonte: Artificial Analysis · USD per 1M token blended
Numero
$8,2
Cosa significa
Più caro nel grafico
Il benchmark va letto insieme al costo: se il task non richiede quel margine, GPT, Gemini o Opus possono essere scelte più razionali.
Cosa scegliere oggi
La scelta pratica parte dal lavoro da fare, non dal primo posto in classifica. Usa Fable 5 se il task è lungo, agentico e abbastanza importante da giustificare consumo rapido del limite o usage credits. Usa Opus 4.8 se vuoi restare in Claude con una scelta premium più equilibrata. Scegli GPT o Gemini quando il tuo workflow vive già in OpenAI, Codex, Workspace, AI Studio o NotebookLM.
- Scegli Fable 5 per task agentici lunghi, difficili da supervisionare e ad alto costo di errore.
- Scegli Opus 4.8 se vuoi restare nell'ecosistema Claude e ti serve continuità su documenti, coding e lavoro premium quotidiano.
- Scegli GPT se contano ChatGPT, Codex, API OpenAI, integrazioni già pronte e un ecosistema molto trasversale.
- Scegli Gemini se usi Workspace, AI Studio, NotebookLM, Antigravity o prodotti Google ogni settimana.
La storia che raccontano i grafici
La lettura più chiara è visiva: Artificial Analysis mostra Fable 5 come modello molto alto per intelligence, ma non come campione di velocità o prezzo. Anthropic evidenzia soprattutto task difficili: coding agentico, knowledge work, tool use, terminale, sicurezza e salute. Quindi il confronto non è una gara unica, ma una mappa dei profili.
- Artificial Analysis: intelligence 65, speed 60 token/s, price blended 8,2 dollari per 1M token nella homepage.
- Anthropic: Fable 5 supera Opus 4.8, GPT-5.5 e Gemini 3.1 Pro in molti benchmark della tabella ufficiale.
- La parte più convincente è il lavoro agentico: SWE-Bench Pro 80,3%, FrontierCode Diamond 29,3%, Terminal-Bench 2.1 88,0%.
- La parte da non ignorare è il costo: il vantaggio aumenta soprattutto quando si accetta più effort e più spesa per task.
Dove Fable sembra davvero avanti
I numeri più coerenti con il posizionamento di Fable sono quelli in cui il modello deve usare strumenti, mantenere contesto, risolvere task lunghi o produrre lavoro verificabile. In questi casi il vantaggio non è solo risposta più bella: è maggiore probabilità di chiudere un task complesso.
- Coding agentico: 80,3% su SWE-Bench Pro contro 69,2% di Opus 4.8 e 58,6% di GPT-5.5.
- Coding duro: 29,3% su FrontierCode Diamond contro 13,4% di Opus 4.8 e 5,7% di GPT-5.5.
- Knowledge work: 1932 su GDPval-AA contro 1890 di Opus 4.8, 1769 di GPT-5.5 e 1314 di Gemini 3.1 Pro.
- Terminale e agenti: 88,0% su Terminal-Bench 2.1, con GPT-5.5 via Codex CLI vicino all'83,4%.
Dove la classifica può ingannare
Il rischio è trasformare una tabella ufficiale in una risposta assoluta. Non tutti i benchmark misurano la stessa cosa: alcuni misurano modello puro, altri un agente con strumenti, altri ancora un workflow con CLI o livelli di effort diversi. Quando cambia il setup, cambia anche la decisione pratica.
- Controlla se il benchmark misura il modello puro o un agente completo.
- Guarda se il risultato usa CLI, tool esterni, retry, livelli di effort o fallback di sicurezza.
- Se il costo per task non è dichiarato, il benchmark dice solo metà della storia.
- Dai più peso ai test che assomigliano al tuo lavoro reale: repo, documenti, terminale, visione o workflow aziendale.
Come scegliere tra Fable, GPT e Gemini
La decisione pratica dovrebbe partire dal workflow, non dal nome del modello. Se lavori in ChatGPT, Codex e strumenti OpenAI, GPT può vincere anche con uno score simile. Se vivi in Workspace, AI Studio, NotebookLM e Antigravity, Gemini può essere più naturale. Se lavori già in Claude e hai un task lungo con criteri di verifica chiari, valuta Fable 5 solo dopo aver controllato se il tuo piano lo include o richiede usage credits.
- Valuta Fable 5 per task lunghi, agentici, difficili da supervisionare e ad alto valore.
- Scegli GPT quando contano ecosistema ChatGPT, Codex, API OpenAI e integrazione con workflow già esistenti.
- Scegli Gemini quando servono Google Workspace, AI Studio, Antigravity, multimodalità e prodotti Google.
- Scegli un modello meno costoso quando il task è breve, ripetitivo o facile da verificare.
La checklist anti-hype
Prima di usare un benchmark per giustificare una scelta, chiediti che cosa misura davvero e cosa manca. Un modello può essere primo su un test e non essere la scelta più economica, disponibile o affidabile per il tuo caso.
- Il benchmark misura il dominio che mi interessa?
- Il test usa strumenti, browsing, codice eseguito o solo risposta testuale?
- Il risultato è single attempt o permette retry?
- Il costo per ottenere quel risultato è dichiarato?
- Il modello è disponibile nel piano o nella regione che posso usare?
- Ci sono fallback, guardrail o limiti che cambiano la performance in produzione?
Domande frequenti
Fable 5 batte GPT e Gemini nei benchmark?
In diversi benchmark ufficiali sì: per esempio SWE-Bench Pro, FrontierCode Diamond, GDPval-AA, Blueprint-Bench 2 e Terminal-Bench 2.1. Questo non significa che sia sempre la scelta migliore: costo, velocità, ecosistema e tipo di task restano decisivi.
Quale benchmark conta di più per scegliere un modello?
Conta quello più simile al tuo lavoro: SWE-Bench o benchmark agentici per coding reale, GPQA e HLE per ragionamento accademico, test multimodali per documenti, immagini e video.
I benchmark ufficiali sono affidabili?
Sono utili, ma vanno letti con cautela. Mostrano il profilo che il provider vuole evidenziare. Meglio incrociarli con leaderboard, paper indipendenti e prove sul proprio workflow.
Quando un benchmark giustifica pagare Fable 5?
Quando il task è lungo, costoso da rifare e simile ai casi in cui Fable mostra vantaggio: agenti, coding complesso, documenti difficili o lavoro con alto costo di errore.
La newsletter di QualeAI
Resta sempre aggiornato sul mondo AI
Ricevi aggiornamenti editoriali sui nostri approfondimenti, tool AI, modelli e workflow da conoscere.
